前言
CTC(Connectionist Temporal Classification)可以在未对输入序列与输出标签进行FA(Force Alignment)的情况下完成时序对齐及分类工作,主要用于语音识别及手写识别[1]。
原理
CTC的工作原理如下图所示[1]:
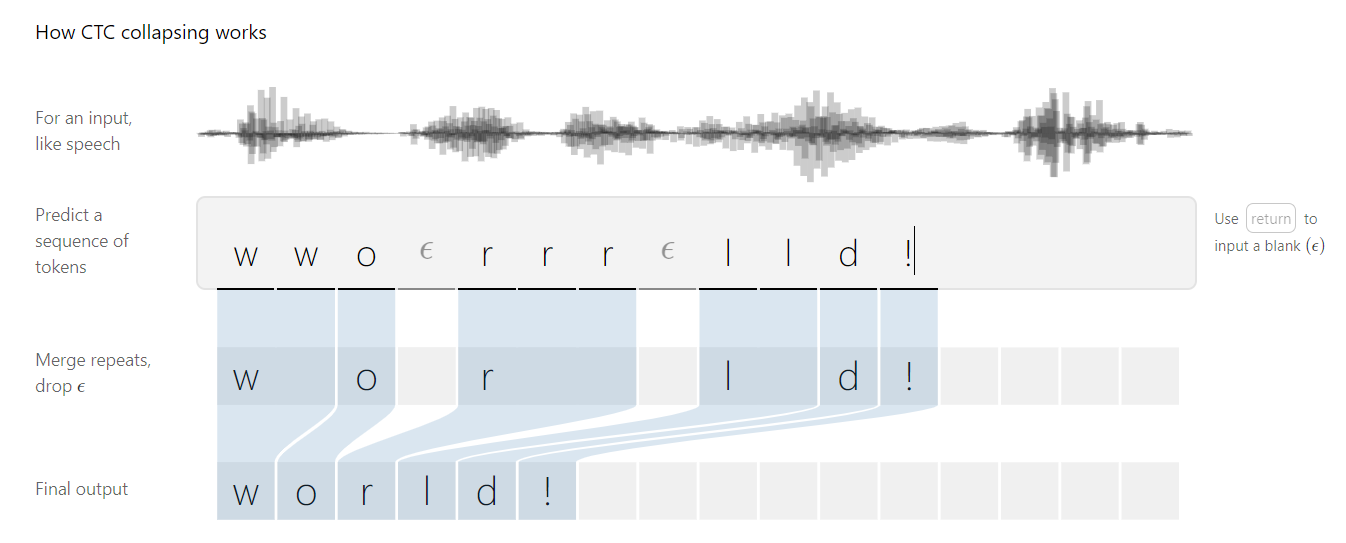
以ASR为例,给定语音信号输入序列$X=[x_1, x_2,…, x_T]$,输出序列记为$Y=[y_1, y_2, …, y_U]$,当前需要找到$X$到$Y$的精确映射。
因以下几点的存在使得寻找映射的工作比较困难:
1)X和Y是可变的序列
2)X和Y的长度比率不是固定的
3)X和Y的对应关系事先无法确定
CTC不仅解决了以上的问题,还基于给定的输入序列$X$得出了$Y$的概率分布,可通过使用该概率分布推断可能的输出或评估输出的概率。
目标:
1)损失函数:驱使概率分布更接近准确的输出,计算Y在给定输入X下的概率分布($P(Y|X)$)
2)推论:最大化$P(Y|X)$,即
时序对齐
论文举例 cat:
实现时序对齐的几个问题:
1)输入和输出可能无法完全对应,比如输入有长时间的静音
2)[h,h,e,l,l,l,o]可能会被识别成helo,实际为hello
为实现时序对齐,解决上述问题,论文提出的方案(remarkable):
作用是指代静音,区分字符相似的单词(如hello和helo)
基于此,hello的输入序列可以表示为[h,h,e,$\epsilon$,$\epsilon$,l,l,l,$\epsilon$,l,l,o],去除重复字符后为[h,e,$\epsilon$,l,$\epsilon$,l,o],去除空白字符后表示为[h,e,l,l,o]
损失函数
CTC使用RNN作为训练网络,在每一步都会生成输出序列的概率分布,其中对于每一对$(X,Y)$,其条件概率为:
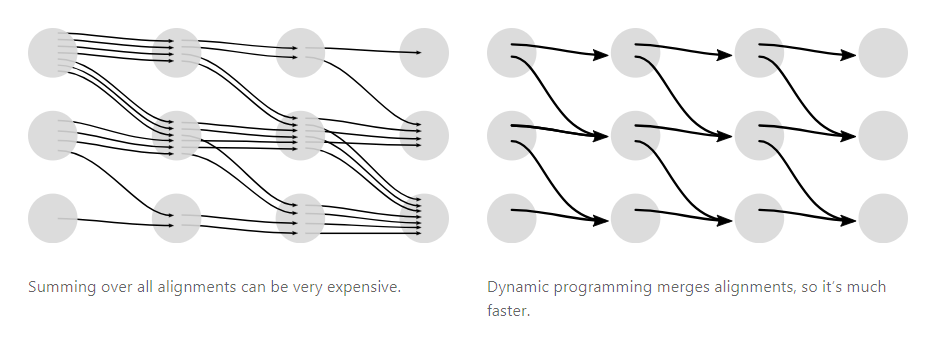
CTC loss的计算十分费时,论文使用动态规划对计算过程进行了优化,合并同一time step的相同输出,如下图所示:
CTC算法的预测序列为
当前字符为空白字符$\epsilon$时,下一个字符有两种可能:空白字符或$Z$序列中的下一个字符。
当前字符不是空白字符时,下一个字符有三种可能:当前字符、空白字符或$Z$序列中的下一个字符。
下图为CTC的计算过程:
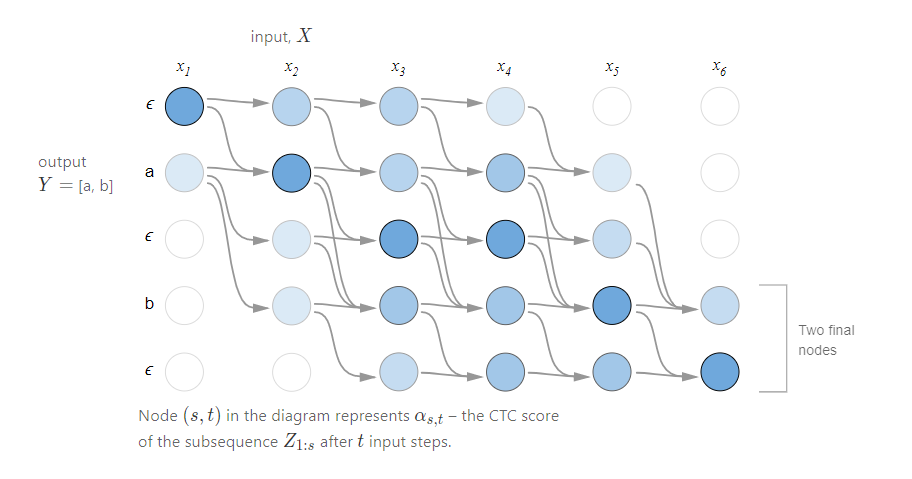
基于动态规划,可用前向和后向概率计算CTC的loss,计算过程可参考[2]。
对于训练集D,CTC的loss计算可归纳为下式:
参考博客[2],CTC的loss函数求解如下图所示:
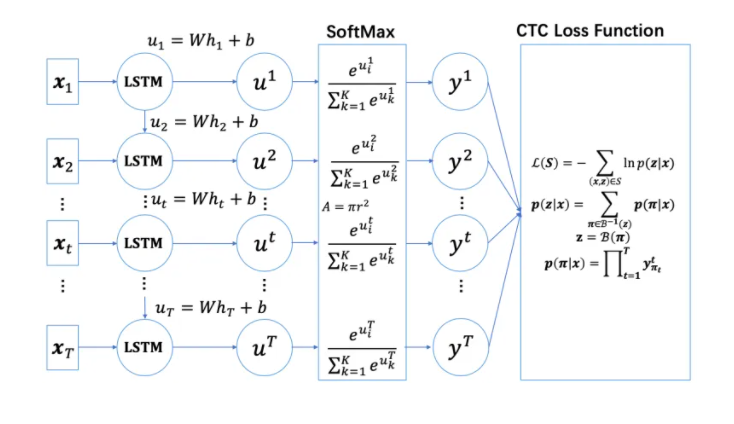
其中的z就是博客前半部分讨论的y,

推论
由于直接暴力计算,$𝒑(𝒛│𝒙)$的复杂度非常高,论文中提及了greedy search和beam search两种方法[3]:
greedy search:每个时间片均取该时间片概率最高的节点作为输出
beam search:Beam Search是寻找全局最优值和Greedy Search在查找时间和模型精度的一个折中
CTC与HMM
作者借鉴HMM的Forward-Backward算法思路,利用动态规划算法求解[2]。
CTC缺陷
CTC假设每个时间片之间是相互独立,这种假设使输出丢失了时间片之间的语义信息,因此在CTC后部添加语言模型可有一定的优化效果。
References
[1] https://distill.pub/2017/ctc/ Sequence Modeling With CTC
[2] https://xiaodu.io/ctc-explained/
[3] https://zhuanlan.zhihu.com/p/42719047