前言
语音信号预处理相关流程简介, 包括预加重、分帧加窗、DFT、FBank等
语音信号提取流程

(python代码可参考References部分的博客)
预加重
Question:为什么需要预加重?
提高信号高频部分的能量,高频信号在传递过程中,衰减较快,包含更多的语音特征,n与n-1的变化幅度更大。
原理
预加重是一个一阶高通滤波器,给定时域输入信号$x[n]$,预加重之后的信号为
当信号为低频信号时,x变化较慢,$x[n]$与$x[n-1]$较为接近,低频信号的幅度会被大大抑制,同理,可保证高频信号特征的传递。
分帧加窗
Question:为什么需要分帧?
1、语音信号为非平稳信号,统计属性随时间变化。
2、语音信号同时具有短时平稳特性,一个声母/韵母的发音往往持续几十到几百毫秒。
3、语音识别以较小发音单元的识别进行,通常为音素、字或字节,需要滑动窗来提取短时片段。
对于采样率为16kHz的信号,帧长、帧移一般为25ms、10ms,即400和160个采样点
帧长是一个窗口的长度,帧移是帧长减去连续两帧之间重叠的部分(overlap)。
原理
分帧的过程,在时域上,即用一个窗函数和原始信号进行相乘:
$w[n]$称为窗函数,常用的窗函数有
矩形窗:
汉明窗(Hamming):
使用汉明窗:加窗的过程,实际上是在时域上将信号截断,窗函数与信号在时域相乘,就等于对应的频域表示进行卷积(*),矩形窗主瓣窄,但是旁瓣较大,将其与原信号的频域表示进行卷积,就会导致频率泄漏
DFT
将上一步分帧之后的语音帧,通过快速傅里叶变换由时域变换到频域,取DFT系数的模,得到谱特征,在此不做详细描述,可参考下列文章(压箱底系列)
DFT: https://zhuanlan.zhihu.com/p/77347644
C语言-FFT蝶形运算:https://zhuanlan.zhihu.com/p/135259438
傅里叶变换的意义: https://blog.csdn.net/guyuealian/article/details/72817527
复数的物理意义: https://www.zhihu.com/question/23234701
信号频域与时域的区别:https://www.zhihu.com/question/21817515
FBank
DFT得到了每个频带上信号的能量,但是人耳对频率的感知不是等间隔的,近似于对数函数
将线性频率转换为梅尔频率,梅尔频率和线性频率转换关系
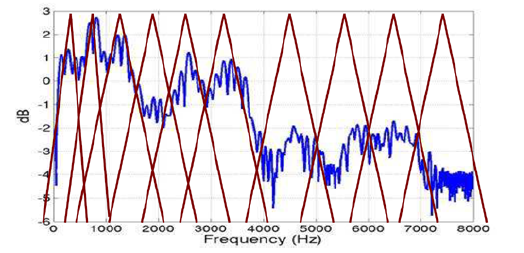
梅尔滤波器组设计
(1)确定滤波器组个数P
(2)根据采样率fs,DFT点数N,滤波器个数P,在梅尔域上等间隔的产生每个滤波器的起始频率、中间频率和截至频率,注意,上一个滤波器的中间频率为下一个滤波器的起始频率(存在overlap)
(3)将梅尔域上每个三角滤波器的起始、中间和截止频率转换线性频率域,并对DFT之后的谱特征进行滤波,得到P个滤波器组能量,进行log 操作,得到Fbank特征
MFCC
MFCC特征组成(以40维为例):
13维静态系数 + 13维一阶差分系数 + 13维二阶差分系数 + 1维帧能量
References
[1]《语音信号预处理及python代码实现博客:
https://www.cnblogs.com/lxp-never/p/10918590.html#blogTitle7》